Mapping Objects to Database Records with ADO.NET
Silan Liu, January
2004
Published by Pinnacle Publishing in volume May 2004
Contents
1 Introduction
This article introduces a method to map OO objects in business logic layer to database records using ADO.NET typed dataset. Database details are totally hidden from business logic. Coding of all layers including data access, business logic and presentation are significantly simplified. OO objects are extremely light-weighted with redundant data. Runtime performance is significantly increased.
There are three following sections in this article. Section “A Use Case” introduces a commonly known “Customer/Order/Product/Delivery” scenario to be used in later chapters. Section “The Data Model” discusses about the architecture of the data model and presents a clear and simple way to adopt it. Section “Discussion” discusses some possible arguments and alternatives. Section “Conclusions” concludes this article.
2 A Use Case
The commonly known “Customer/Order/Product/Delivery” scenario is depicted in the following UML class diagram:
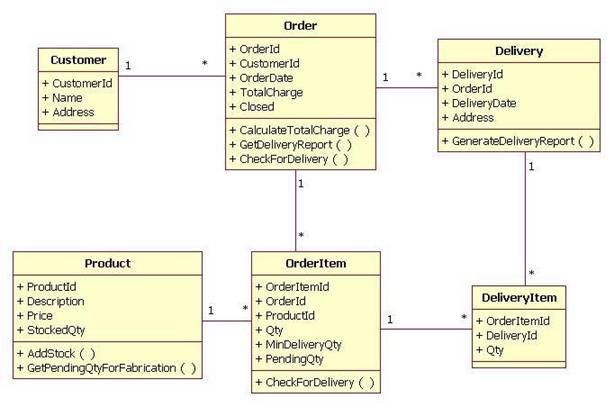
Fig.
1. UML class diagram of the use case
Customer makes an order which contains several order items i.e. products. One order item can be delivered multiple times – customer may place an order for 30 laptop computers, and ask the supplier to ship whenever 10 is available. This is the MinDeliveryQty of entity OrderItem. The rest of the entity fields explain themselves.
Some behaviour are combined with the data to form OO objects. Method Order.CheckForDelivery, for example, goes through all order items included in this order and find the stocked quantity of the corresponding products. If the stocked quantity is more than MinDeliveryQty, make a new delivery.
This scenario will be used in the rest of the article. The code included in this article are cited from a runnable application based on this scenario, which can be downloaded at _________________.
3 The Data Model
A typical architecture of an application using this data model is shown in Fig. 1:
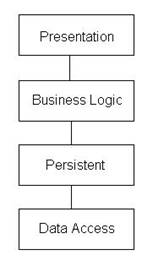
Fig. 2.
Architecture of the data model
3.1 Data Access Layer
The data access tier has nothing special. It generates a strongly typed dataset from data retrieved from database, and returns it to the Persistent layer. It also accepts a strongly typed dataset containing records marked as added, deleted or modified from the Persistent layer, and submits the changes to the database. The XSD definition of the strongly typed dataset, which can be either composed manually or generated automatically from the database schema, is also defined in this layer. In the example used in this article, the dataset class is called DS.
3.2 Persistent Layer
Persistent layer is an extra layer (in form of a DLL) required by this data model. It has a class for each of the data entities (Customer, Order, Product, OrderItem, Delivery, DeliveryItem). Such classes all have a prefix “P”, such as POrder and PProduct.
Normally, each OO class in the business logic has matching data members for the columns in the corresponding database table. For example, class Order will have data member OrderId, CustomerId, OrderDate, TotalCharge and Closed. This results in redundant data being stored in the OO objects, which need to be synchronized every now and then with data stored in the dataset using serialization/deserialization techniques. It can be quite complicated and error-prone.
In most cases, there are data relations between most of the data entities, represented by the foreign keys. For example, an OrderItem has two foreign keys: ProductId and OrderId, which means that an order item must belong to an existing product and an existing order. It also means that we have to provide navigation abilities for the classes – an OrderItem object should be able to find its corresponding Product and Order object, and an Order object should be able to find all of its OrderItem objects.
In comparison, in this data model, OO classes does not have any data member for the table columns. Instead, each “P” class in the Persistent layer simply holds a strongly typed data row, which are defined in the same XSD of the typed dataset. For example, class POrder holds a member of type DS.OrderRow, and class PDelivery holds a DS.DeliveryRow. As an example, the code of POrder is shown bellow:
using System;
namespace NsPersistent
{
public class POrder
{
protected DS.OrderRow mDataRow = null;
internal POrder(DS.OrderRow dataRow)
{
mDataRow = dataRow;
}
public
POrder(int iCustomerId, DateTime orderDate)
{
mDataRow = DS.Order.NewOrderRow();
mDataRow.CustomerId = iCustomerId;
mDataRow.OrderDate
= orderDate;
mDataRow.Closed = false;
DataSetManager.DS.Order.AddOrderRow(mDataRow);
}
public void Delete()
{
mDataRow.Table.Rows.Remove(mDataRow);
mDataRow = null;
}
public
PCustomer GetCustomer()
{
return new PCustomer(mDataRow.CustomerRow);
}
public
POrderItem AddOrderItem(int iProductId, int iQty, int
iMinDeliveryQty)
{
NsPersistent.DS.OrderItemRow row =
DataSetManager.DS.OrderItem.NewOrderItemRow();
row.OrderId = mDataRow.OrderId;
row.ProductId = iProductId;
row.Qty = iQty;
row.MinDeliveryQty = iMinDeliveryQty;
row.PendingQty = iQty;
DataSetManager.DS.OrderItem.AddOrderItemRow(row);
return new POrderItem(row);
}
public
POrderItem [] GetOrderItems()
{
DS.OrderItemRow [] aRows =
mDataRow.GetOrderItemRows();
POrderItem [] aPersistents = new POrderItem[aRows.Length];
for (int i = 0; i < aRows.Length; i++)
{
aPersistents[i] = new POrderItem(aRows[i]);
}
return
aPersistents;
}
public
PDelivery MakeDelivery(DateTime deliveryDate, string
strAddress)
{
DS.DeliveryRow row =
DataSetManager.DS.Delivery.NewDeliveryRow();
row.OrderId = mDataRow.OrderId;
row.DeliveryDate = deliveryDate;
row.Address = strAddress;
DataSetManager.DS.Delivery.AddDeliveryRow(row);
return new PDelivery(row);
}
public
PDelivery [] GetDeliveries()
{
DS.DeliveryRow [] aRows =
mDataRow.GetDeliveryRows();
PDelivery [] aPersistents = new PDelivery[aRows.Length];
for (int i = 0; i < aRows.Length; i++)
{
aPersistents[i] = new PDelivery(aRows[i]);
}
return
aPersistents;
}
public int OrderId
{
get { return mDataRow.OrderId; }
}
public int CustomerId
{
get { return mDataRow.CustomerId; }
}
public
DateTime OrderDate
{
get { return mDataRow.OrderDate; }
}
public
Decimal TotalCharge
{
get { return mDataRow.TotalCharge; }
set {
mDataRow.TotalCharge = value; }
}
public bool Closed
{
get { return mDataRow.Closed; }
set { mDataRow.Closed = value;
}
}
}
}
These “P” classes do not have any business logic. They only expose the typed fields of the typed data rows as public properties. They also expose all data relation navigation methods. From their interfaces client can see absolutely no reference to database or dataset. There is one constructor which takes a typed data row as a parameter. This is needed by the navigation methods of peer “P” classes (eg. the above POrder.GetOrderItems method needs to create POrderItem objects out of DS.OrderItemRows). Luckily, the internal compiler keyword helps to hide this constructor from clients outside the DLL. This way, these “P” classes completely hides database/dataset details from the business logic programmers, and they themselves are perfect OO objects.
And, behold! All the synchronization, serialization and navigation problems are solved!
The data row members held by the “P” classes are only pointers to the concrete data rows in the dataset. Any set or get operation done to these members are done directly to the data in the dataset. Therefore, a “P” class does not contain any redundant data and has almost zero memory foot print. You can afford to create a big array of such objects and pass them around at your convenience. It also saves all the hassles of synchronizations and serialization/deserialization.
These typed data rows know all its data relations. For example, a DS.OrderRow has a GetOrderItemRows method and a CustomerRow property to get the parent and child rows. The navigation problem is also solved for you.
This data model also reduces size of the messages between classes/components. Suppose you need to call another component which processes an order for you and therefore needs all information about this order. Without this built-in navigation ability, how much information do you have to pass to that component? The customer making this order, all order items in this order, all corresponding products, all deliveries that have been made for this order, delivery items in these deliveries... A big chunk of memory being copied and sent, isn’t it? Not mentioning that after the processing component modifies these objects or creates new ones, all of these data have to be passed back to the caller.
Now, with this data model, what do you need to pass to the processing component? One order object, nothing else. Because the processing component is able to interrogate this order object to acquire all its related objects, and so on. And what needs to be passed back? None. Because all modifications and new objects have been directly written to the dataset.
All the properties exposed by the typed data rows are typed. So you get compiler-time type checking.
This is how the mapping between OO objects and database records is done. All in one line of code – by aggregating a typed data row offered by ADO.NET.
Apart from the “P” classes, there is a DataSetManager in the Persistent layer, which holds the one typed dataset as a static member for all “P” classes to access, and is responsible to load and submit the dataset, and answer queries such as “give me all orders that are closed”, “give me all products that has pending orders”. Its GetAllOrders method looks like
static public POrder [] GetAllOrders(OrderType orderType)
{
DataAccessService.DS.OrderRow []
aOrderRows = null;
switch
(orderType)
{
case
OrderType.All:
aOrderRows =
(DataAccessService.DS.OrderRow [])(mds.Order.Select(""));
break;
case
OrderType.Closed:
aOrderRows =
(DataAccessService.DS.OrderRow [])(mds.Order.Select("Closed=1"));
break;
case
OrderType.Pending:
aOrderRows =
(DataAccessService.DS.OrderRow [])(mds.Order.Select("Closed=0"));
break;
}
POrder [] aOrders = new POrder[aOrderRows.Length];
for (int i = 0; i < aOrderRows.Length; i++)
{
aOrders[i] = new POrder(aOrderRows[i]);
}
return
aOrders;
}
3.3 Business Logic Layer
An OO object in business logic layer normally has more behaviour than the navigation methods provided by the “P” classes in Persistent layer. For example, as shown in Fig. 1, entity Order has four business logic methods: OrderReceived, CalculateTotalCharge, GetDeliveryReport and CheckForDelivery. Therefore, for each “P” class in the Persistent layer, there is a corresponding class in the business logic layer, such as Order for POrder, Product for PProduct. Each holds a “P” class object, some wrapper methods to expose the properties and navigation methods provided by the “P” class, plus the business logic behaviours. I call them Persistent Business Logic Classes (PBL).
The code of a PBL class Order was shown bellow. Have a look at the business logic methods, see how much simpler and natural the coding has become using this data model:
using System;
using System.Collections;
namespace NsBusinessLogic
{
public class Order
{
protected NsPersistent.POrder mPersistent = null;
static protected Delivery mCurrentDelivery = null;
protected Order(int iCustomerId, DateTime orderDate)
{
mPersistent = new
NsPersistent.POrder(iCustomerId, orderDate);
}
public
Order(NsPersistent.POrder persistent)
{
mPersistent = persistent;
}
//********************
Business logic methods ******************
/* OrderReceived
is sent a XML string order as follow:
<Order CustomerId="2"
Date="25/12/2003">
<Product Id="3"
Qty="10" MinimumDeliveryQty=10/>
<Product Id="5"
Qty="15" MinimumDeliveryQty=10/>
<Product Id="6"
Qty="20" MinimumDeliveryQty=10/>
</Order>
*/
static public Order OrderReceived(string
strOrder)
{
System.Xml.XmlDocument doc = new System.Xml.XmlDocument();
doc.LoadXml(strOrder);
System.Xml.XmlNode rootNode =
doc.DocumentElement;
int
iCustomerId = Convert.ToInt32(rootNode.Attributes["CustomerId"].Value);
DateTime orderDate =
DateTime.Parse(rootNode.Attributes["Date"].Value);
System.Xml.XmlNode productNode = null;
Order order = new
Order(iCustomerId, orderDate);
if
(rootNode.HasChildNodes)
{
productNode = rootNode.FirstChild;
while
(productNode != null)
{
order.AddOrderItem(
Convert.ToInt32(productNode.Attributes["Id"].Value),
Convert.ToInt32(productNode.Attributes["Qty"].Value),
Convert.ToInt32(productNode.Attributes["MinimumDeliveryQty"].Value));
productNode =
productNode.NextSibling;
}
}
order.CalculateTotalCharge();
return
order;
}
protected
Decimal CalculateTotalCharge()
{
NsPersistent.POrderItem [] aPersistents
= mPersistent.GetOrderItems();
Decimal dcTotal = 0;
foreach
(NsPersistent.POrderItem orderedProduct in
aPersistents)
{
dcTotal += orderedProduct.Qty *
orderedProduct.GetProduct().Price;
}
mPersistent.TotalCharge = dcTotal;
return
dcTotal;
}
/// <summary>
/// Get the XML report of the delivery history of each order
item.
/// </summary>
public string GetDeliveryReport()
{
OrderDeliveryReport report = new OrderDeliveryReport();
System.Xml.XmlNode orderNode =
report.AddOrderElement(
mPersistent.OrderId,
mPersistent.GetCustomer().Name,
mPersistent.GetCustomer().Address,
mPersistent.OrderDate);
NsPersistent.POrderItem [] aOrderItems
= mPersistent.GetOrderItems();
System.Xml.XmlNode productNode = null;
foreach
(NsPersistent.POrderItem orderItem in
aOrderItems)
{
productNode =
report.AddProductElement(orderNode, orderItem.GetProduct().ProductId,
orderItem.GetProduct().Description,
orderItem.Qty);
foreach
(NsPersistent.PDeliveryItem deliveryItem in
orderItem.GetItemDeliveries())
{
report.AddDeliveryElementToProductElement(productNode,
deliveryItem.Qty,
deliveryItem.GetDelivery().DeliveryDate);
}
}
return
report.GetXmlString();
}
/// <summary>
/// Go through all order items and call their own
CheckForDelivery methods. If a delivery
/// is due, generate the delivery report to be used as
delivery document.
/// </summary>
public void CheckForDelivery()
{
if
(mPersistent.Closed == true)
throw
new Exception("Order
closed!");
OrderItem [] aOrderItems =
GetOrderItems();
bool
fOrderClosed = true;
foreach
(OrderItem orderItem in aOrderItems)
{
if
(orderItem.PendingQty > 0)
{
orderItem.CheckForDelivery();
if
((orderItem.PendingQty > 0) && (fOrderClosed == true))
fOrderClosed = false;
}
}
if
(fOrderClosed)
mPersistent.Closed = true;
if
(mCurrentDelivery != null)
{
mCurrentDelivery.GenerateDeliveryReport();
mCurrentDelivery = null;
}
}
public
Delivery CurrentDelivery
{
get
{
if
(mCurrentDelivery == null) MakeDelivery();
return
mCurrentDelivery;
}
}
static public Order [] GetAllOrders(NsPersistent.OrderType
orderType)
{
NsPersistent.POrder [] aPersistents =
NsPersistent.DataSetManager.GetAllOrders(orderType);
Order [] aOrders = new Order[aPersistents.Length];
for (int i = 0; i < aPersistents.Length; i++)
{
aOrders[i] = new Order(aPersistents[i]);
}
return
aOrders;
}
//****************
Persistent properties & Navigation methods ****************
public
NsPersistent.POrder Persistent
{
get { return mPersistent; }
}
protected
OrderItem AddOrderItem(int iProductId, int iQty, int
iMinDeliveryQty)
{
return new OrderItem(mPersistent.AddOrderItem(iProductId,
iQty, iMinDeliveryQty));
}
public
OrderItem [] GetOrderItems()
{
NsPersistent.POrderItem [] aPersistents
= mPersistent.GetOrderItems();
OrderItem [] aOrderItems = new OrderItem[aPersistents.Length];
for (int i = 0; i < aPersistents.Length; i++)
{
aOrderItems[i] = new OrderItem(aPersistents[i]);
}
return
aOrderItems;
}
public Delivery
MakeDelivery()
{
mCurrentDelivery = new Delivery(mPersistent.MakeDelivery(DateTime.Now,
mPersistent.GetCustomer().Address));
return
mCurrentDelivery;
}
}
}
PBL classes does not know any database or dataset stuff, they only use “P” classes in Persistent layer. While All other classes in the business logic layer even don’t know the “P” classes. What they are dealing with are PBL classes with all data and behaviours perfectly encapsulated.
In the presentation tier, suppose user is presented with a form containing some textboxes and datagrids bound to the dataset. User makes some changes, and finally decides to give up the changes by clicking the “Cancel” button. Do we need a data cache for this scenario? No. All you have to do is to call the dataset’s RejectChanges method.
You may have noticed that apart from the XML report or XML order that are from or for human, in all the internal processes of the application, programmer never need to deal with the IDs (CustomerId or ProductId or DeliveryId etc.) They are all hidden within the seamless implementation of the typed dataset and data rows.
4 Discussions
There are plenty of researches done in mapping OO objects to database records, including some cater-for-all approaches, with a data access layer automatically dissecting all types of objects using their metadata and writing their fields into corresponding database tables. With such a library in hand, programmers do not need to write any database-aware code or even have any database knowledge – theoretically.
Such solutions are usually based on some sort of a smart twist. Such twists also impose limitations on how users can do things, and can not leverage many if not most of the functionalities provided by the framework such as ADO.NET. And they are usually complicated and opaque. If once finished they are really cater-for-all and 100% bug-free they are still worth making, but in reality when facing a different use case people usually find that the cater-for-all model still needs a bit “fine tuning” to cater for the new case. Because of the complexity this “fine tuning” usually takes quite a bit of effort and expertise. The complexity increases exponentially with extra functionalities added in. Eventually, developers basically found themselves rewriting ADO.NET, with many times more code size and complexity.
The drive forces for having such cater-for-all data model are mainly to achieve code reuse and free programmers from complicated and error-prone database manipulations. With the coming of ADO.NET, these two drive forces become a lot weaker. ADO.NET greatly reduced the work load and complexity of database manipulations. Writing specific code for every specific project is no longer a big pain.
Especially, the data model introduced in this article has a highly standardized and decoupled architecture, making copy-and-paste across projects very easy. For example, the first project I designed using this model was for a optical spectroscopy machine, with entities like Datasheet, Solution, Isotope, IntensityCell, IntensityReplicate, PlasmaCondition, etc. I spent 50 ~ 70 hours to code the Data Access and Persistent layer. When I was coding this totally different commercial “Customer/Order/Product” application, I found I was able to reuse most of the architecture and code of that optical spectroscopy application. What I did most was to use the search-and-replace function of the editor to change entity names and data types. I completed the same job in six or seven hours.
This data mode does not place any limitation on how user does things, because it is the most natural and logical way to map database records to OO objects using the underlying ADO.NET framework. Users are provided with highly standardized and easy-to-follow model, and yet left with all the options, functionalities and flexibilities provided by the framework.
There might be an accusation that, the use of the “P” classes that do not yet have business logic behavour encapsulated, or the fact that the real data is not physically stored with the object, is a sign of separation of behaviour and data. I would argue that as long as you don’t store all the method definitions in the database records, the data and the behaviours are separated at certain stages anyway. What is important is when the PBL objects are put into use, their data and behavours are always well encapsulated. Whether the data is in concrete or refernce format does not matter at all.
5 Conclusions
The data model discussed in this article has the following advantages:
· Database and dataset implementations are totally hidden from the business logic layer. OO objects (PBL classes) are perfect OO objects.
· Objects are extremely light-weighted in both runtime memory foot print and code size.
· No synchronization and serialization/deserialization is needed
· Compile-time type/integrity checking are done at all levels.
· The model is the most natural and logical way to do the job. It does not exert any limitation on how it is used. Developers are left with all options and flexibilities to use it or extend it.
· The model is transparent, so maintainability is good.